Unseen skill
(Select an example)
Jailbreaks keep appearing, but many “new” prompts quietly reuse the same underlying tactics. We ask: are novel jailbreaks actually recompositions of a finite skill set?
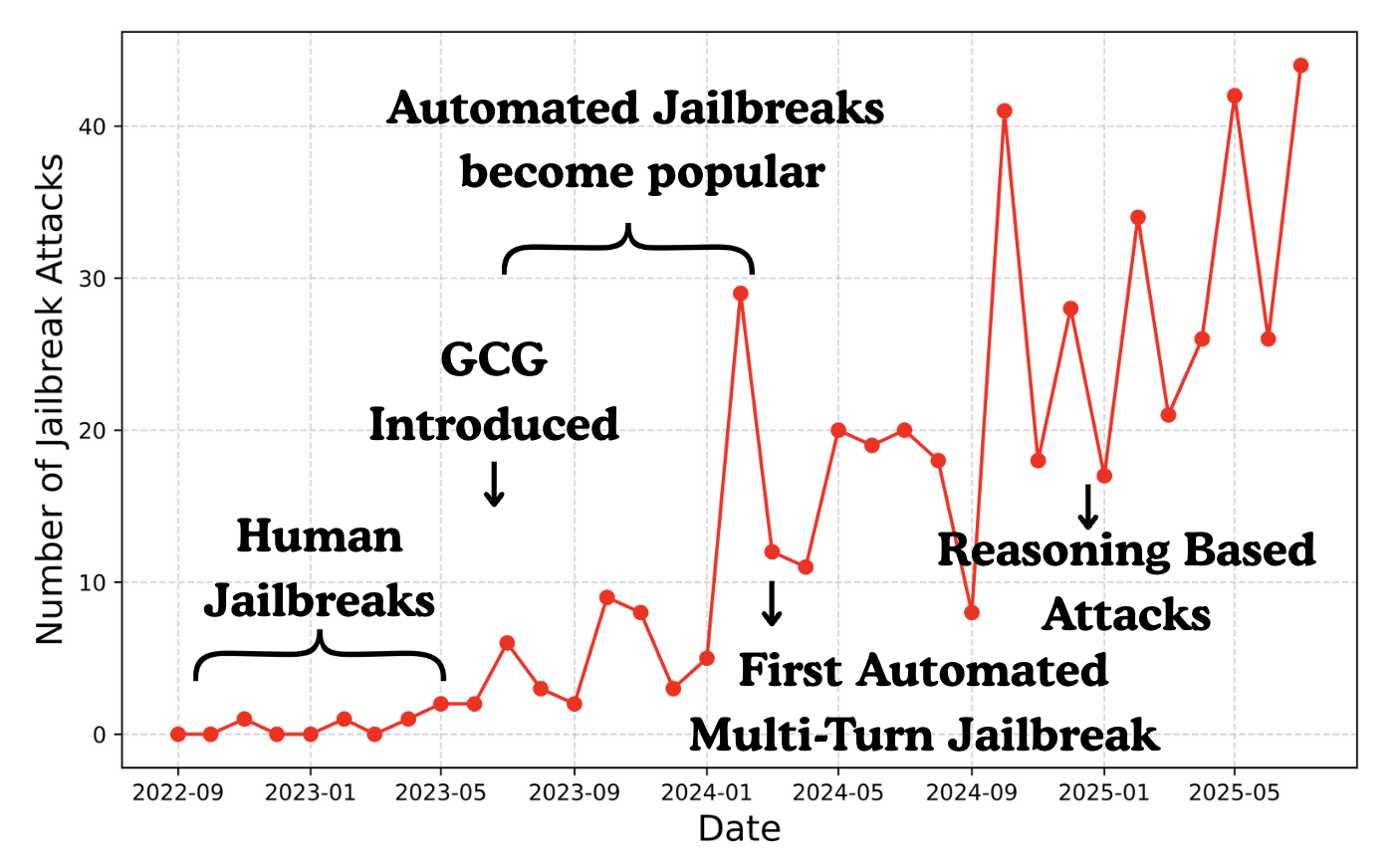
Fig. 1a. Jailbreaks arrive in waves, not one-offs.

Fig. 1b. Different attacks often reuse the same skill (e.g., academic-facade framing).
We treat jailbreaks as compositions of adversarial skills, not isolated tricks. From 32 papers (Nov 2022 – Nov 2024), we extract 16,901 skills and compress them into a compact Jailbreak Dictionary (~397 primitives).
To test generalization, we set a temporal cutoff (Aug 15 2024): pre-cutoff attacks build the dictionary; post-cutoff attacks evaluate whether unseen skills can be reconstructed from earlier primitives.
The Jailbreak Dictionary captures the building blocks of adversarial behavior — a compact set of transferable skills that explain how different jailbreaks succeed. It transforms a scattered collection of attacks into an interpretable skill space we can analyze and build defenses on.
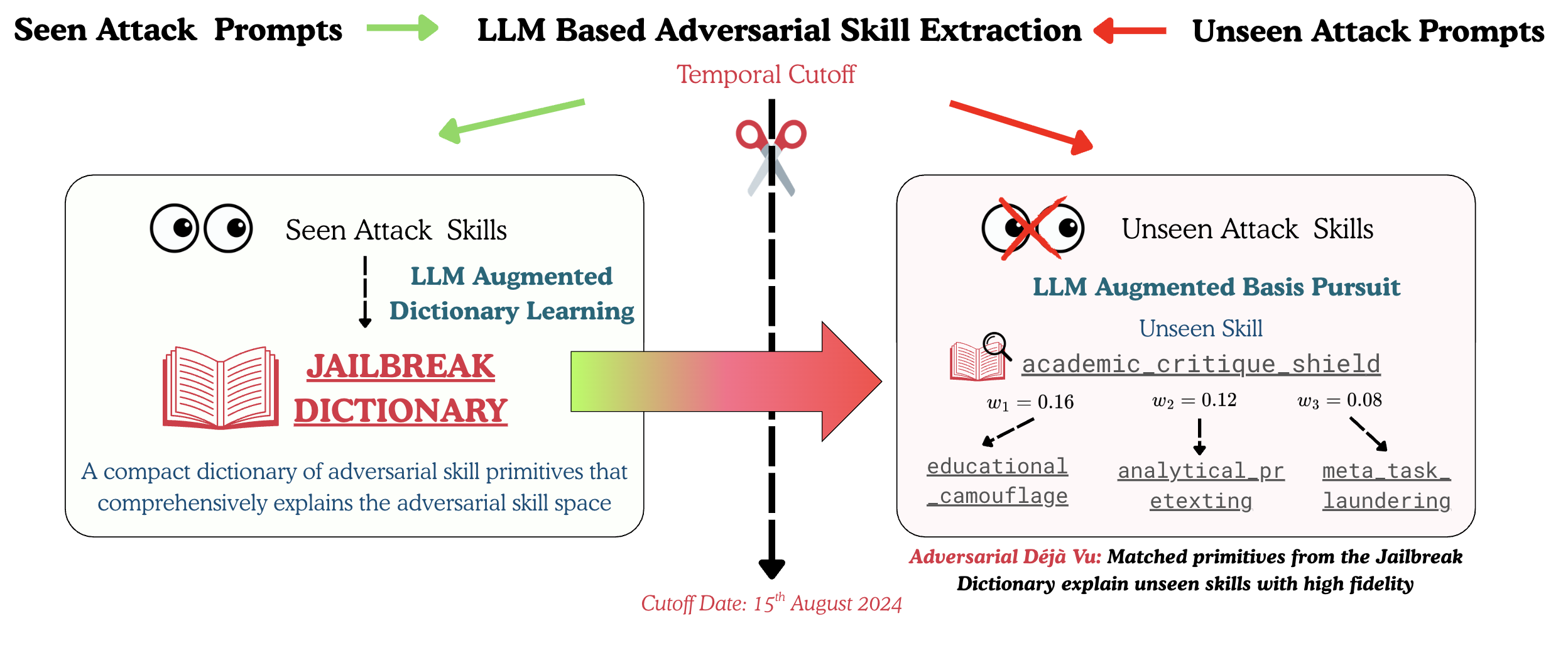
Fig. 2. From pre-cutoff attacks to a compact, named dictionary of skill primitives.
The dictionary preserves explanatory power even after heavy compression, reconstructing unseen skills with only ~5–7 active primitives on average.
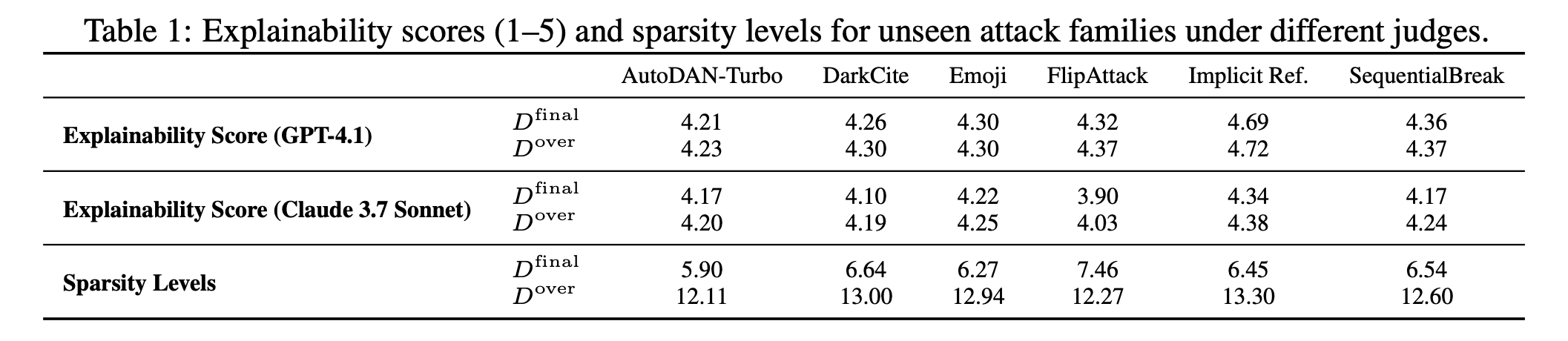
Table 1. High explainability at low sparsity.
As more attacks are seen, explainability rises and then plateaus (~4.3–4.4), indicating diminishing novelty — the core evidence for Adversarial Déjà Vu.
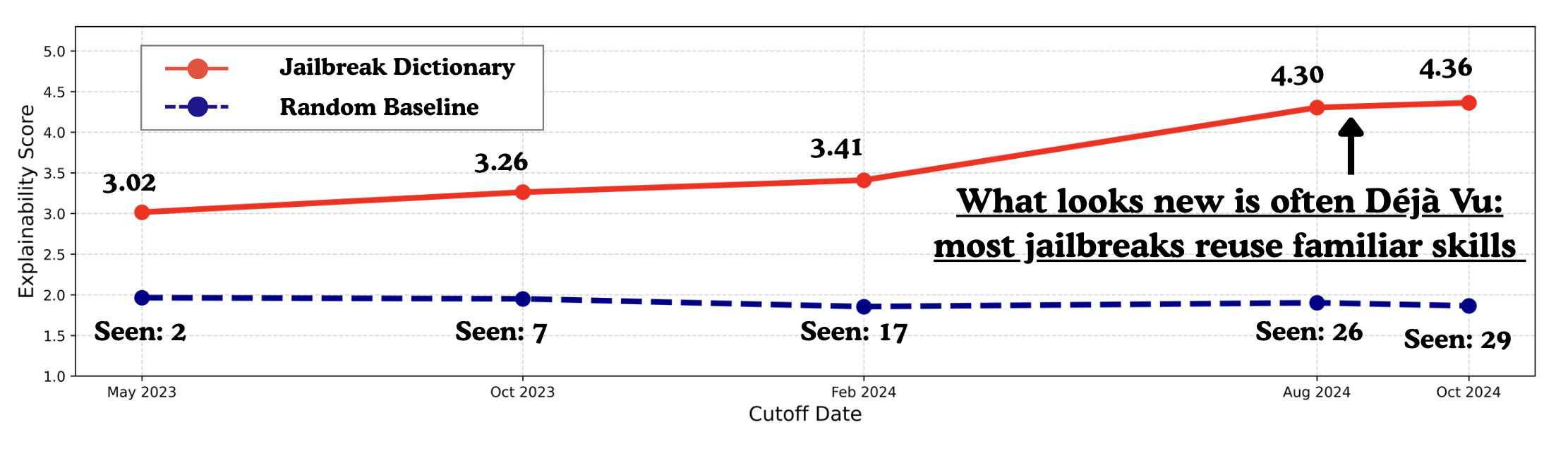
Fig. 3. Explainability increases then saturates.
If new jailbreaks are just recombinations of familiar skills, then defenses should learn from those combinations. ASCoT (Adversarial Skill Compositional Training) teaches models to recognize and resist diverse skill mixtures — moving beyond memorizing attacks to mastering the underlying adversarial strategies. This directly targets the mechanisms that transfer across families (deception, framing, obfuscation, etc.), improving robustness to unseen jailbreaks while keeping refusals calibrated.

Fig. 4. Example of composing two primitives to mutate a base query.
Across LLaMA-3.1-8B and Zephyr-7B, ASCoT lowers harmfulness and strengthens generalization to unseen attacks, while keeping over-refusal balanced.
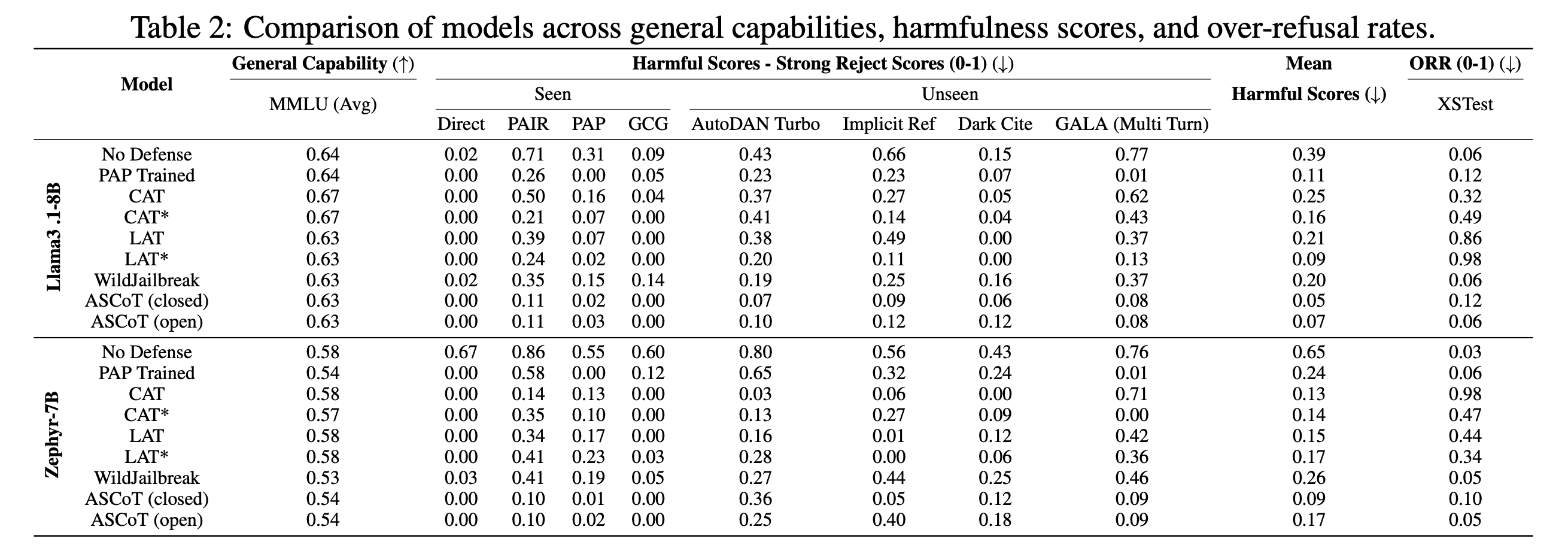
Table 2. ASCoT achieves strong robustness–utility balance.
Compared to closed-source reasoning models, the open-weight ASCoT model is competitive — and even surpasses o4-mini on most families — with similar over-refusal rates.

Table 3. Open-weight ASCoT competes with closed-source reasoning models.
Robustness comes from two places. First, the more adversarial skills we cover in training, the fewer surprises an attacker can invent. Second, models must learn to handle compositions of skills — simple defenses stop short at one-trick prompts, but defending against sophisticated, multi-step attacks requires exposure to deeper, multi-skill combinations.
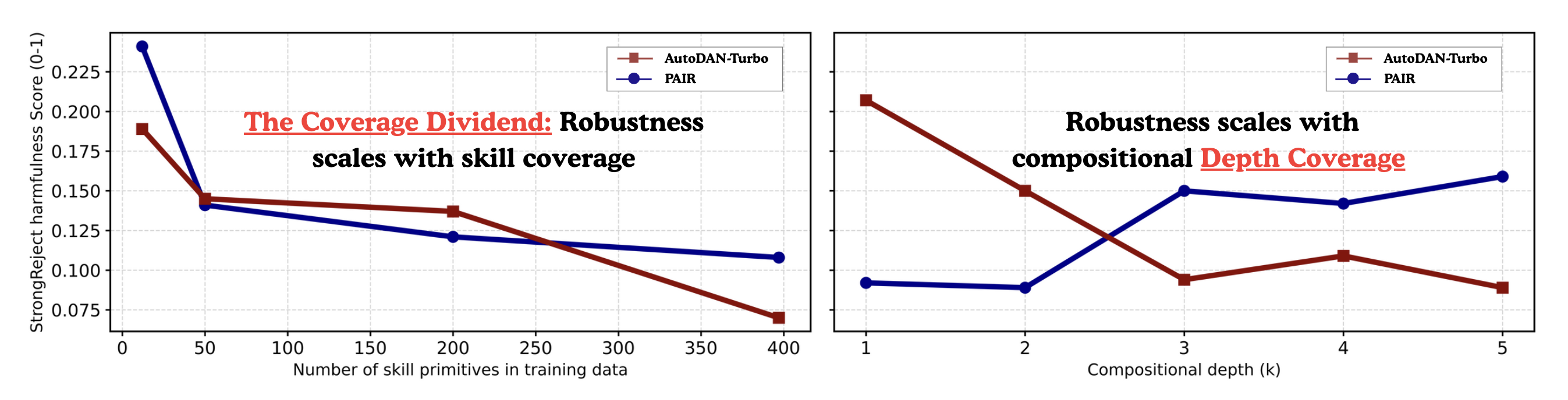
Fig. 5. Coverage pays off; depth aligns defenses with attack complexity.
Finally, ASCoT sits at a favorable point on the robustness–utility curve, reducing harmful responses without inducing excessive refusals.
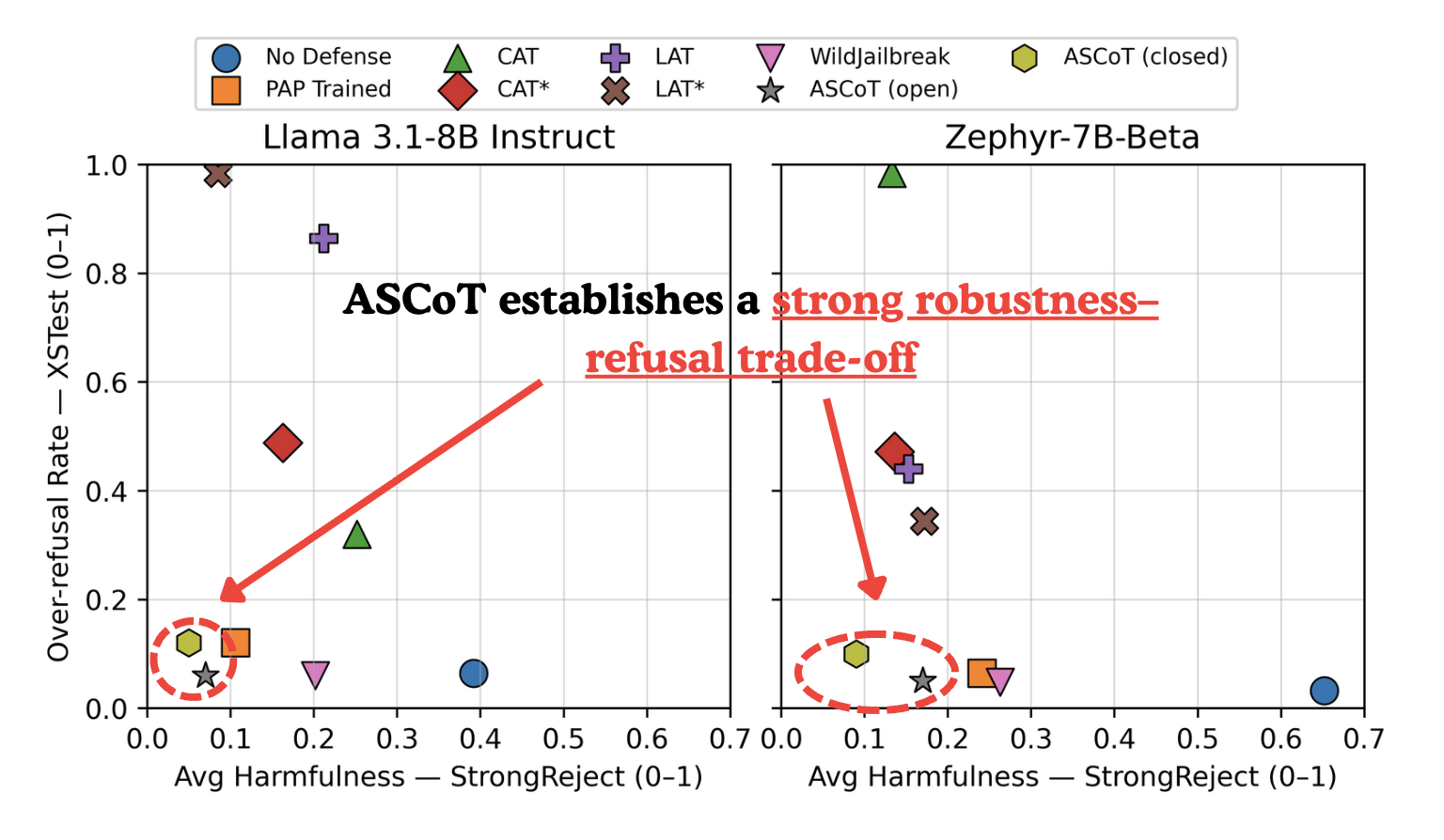
Fig. 6. Robustness increases without a refusal spike.
Robustness scales with coverage and compositional diversity of adversarial skills — not just model size or raw data. By learning a compact set of transferable adversarial skill primitives and training on their compositions, Adversarial Déjà Vu and ASCoT offer a scalable, generalizable path to defending against unseen jailbreaks.
Below are concrete examples illustrating our skill-extraction pipeline: for each instance we show the original harmful prompt, the mutated jailbreak prompt, and two example skill atoms identified by our pipeline, presented as a JSON-like object.
(select an example)
(select an example)
(select an example)
For each unseen skill (from a post-cutoff attack), we show the top matches in our Jailbreak Dictionary — including the primitive’s name, definition, example, and attribution weight.
| Skill name | Definition | Example | Weight |
|---|---|---|---|
| (Select an example) | |||
This section presents concrete examples of how named skill primitives compose to generate a mutated (attacker-style) query. Each example includes the original harmful prompt, the composing skills, and the resulting composed prompt.
(Select an example)
(Select an example)
This work investigates adversarial jailbreak behavior in large language models (LLMs) through the lens of transferable adversarial skill primitives. Our goal is to advance the scientific understanding of how such attacks generalize, thereby enabling the development of more principled and proactive defenses. While studying jailbreaks may incidentally expose mechanisms that could be repurposed for harmful use, we have taken extensive precautions to prevent misuse.
We adhere to responsible disclosure practices: all experiments were conducted on locally hosted models in controlled research environments. No attempts were made to disseminate, deploy, or amplify harmful generations.
Our research explicitly seeks to improve societal safety by reframing robustness as generalization across the adversarial skill space rather than mere suppression of harmful text. We believe that open, responsible examination of the mechanisms that enable jailbreaks is essential for building transparent, resilient, and trustworthy foundation models.
If you find our project useful, please consider citing:
@misc{dabas2025adversarialdejavujailbreak,
title={Adversarial D\'ej\`a Vu: Jailbreak Dictionary Learning for Stronger Generalization to Unseen Attacks},
author={Mahavir Dabas and Tran Huynh and Nikhil Reddy Billa and Jiachen T. Wang and Peng Gao and Charith Peris and Yao Ma and Rahul Gupta and Ming Jin and Prateek Mittal and Ruoxi Jia},
year={2025},
eprint={2510.21910},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2510.21910},
}